
As a result of their high model capability, Vision Transformer models have enjoyed a fantastic deal of success in recent times. Despite their performance, vision transformers models have one major flaw: their remarkable computation prowess comes at high computation costs, and it’s the rationale why vision transformers will not be the primary alternative for real-time applications. To tackle this issue, a gaggle of developers launched EfficientViT, a family of high-speed vision transformers.
When working on EfficientViT, developers observed that the speed of the present transformer models is commonly bounded by inefficient memory operations, especially element-wise functions & tensor reshaping in MHSA or Multi-Head Self Attention network. To tackle these inefficient memory operations, EfficientViT developers have worked on a brand new constructing block using a sandwich layout i.e the EfficientViT model makes use of a single memory-bound Multi-Head Self Attention network between efficient FFN layers that helps in improving memory efficiency, and in addition enhancing the general channel communication. Moreover, the model also discovers that spotlight maps often have high similarities across heads that results in computational redundancy. To tackle the redundancy issue, the EfficientViT model presents a cascaded group attention module that feeds attention heads with different splits of the total feature. The strategy not only helps in saving computational costs, but in addition improves the eye diversity of the model.
Comprehensive experiments performed on the EfficientViT model across different scenarios indicate that the EfficientViT outperforms existing efficient models for computer vision while striking trade-off between accuracy & speed. So let’s take a deeper dive, and explore the EfficientViT model in a little bit more depth.
Vision Transformers remain one of the vital popular frameworks in the pc vision industry because they provide superior performance, and high computational capabilities. Nevertheless, with continuously improving accuracy & performance of the vision transformer models, the operational costs & computational overhead increase as well. For instance, current models known to supply state-of-the-art performance on ImageNet datasets like SwinV2, and V-MoE use 3B, and 14.7B parameters respectively. The sheer size of those models coupled with the computational costs & requirements make them practically unsuitable for real-time devices & applications.
The EfficientNet model goals to explore the way to boost the performance of vision transformer models, and finding the principles involved behind designing efficient & effective transformer-based framework architectures. The EfficientViT model is predicated on existing vision transformer frameworks like Swim, and DeiT, and it analyzes three essential aspects that affect models interference speeds including computation redundancy, memory access, and parameter usage. Moreover, the model observes that the speed of vision transformer models in memory-bound, which implies that full utilization of computing power in CPUs/GPUs is prohibited or restricted by memory accessing delay, that leads to negative impact on the runtime speed of the transformers. Element-wise functions & tensor reshaping in MHSA or Multi-Head Self Attention network are probably the most memory-inefficient operations. The model further observes that optimally adjusting the ratio between FFN (feed forward network) and MHSA, may also help in significantly reducing the memory access time without affecting the performance. Nevertheless, the model also observes some redundancy in the eye maps in consequence of attention head’s tendency to learn similar linear projections.
The model is a final cultivation of the findings through the research work for the EfficientViT. The model includes a recent black with a sandwich layout that applies a single memory-bound MHSA layer between the Feed Forward Network or FFN layers. The approach not only reduces the time it takes to execute memory-bound operations in MHSA, nevertheless it also makes the whole process more memory efficient by allowing more FFN layers to facilitate the communication between different channels. The model also makes use of a brand new CGA or Cascaded Group Attention module that goals to make the computations simpler by reducing the computational redundancy not only in the eye heads, but in addition increases the depth of the network leading to elevated model capability. Finally, the model expands the channel width of essential network components including value projections, while shrinking network components with low value like hidden dimensions within the feed forward networks to redistribute the parameters within the framework.
As it will probably be seen within the above image, the EfficientViT framework performs higher than current state-of-the-art CNN and ViT models by way of each accuracy, and speed. But how did the EfficientViT framework manage to outperform among the current state-of-the-art frameworks? Let’s find that out.
EfficientViT: Improving the Efficiency of Vision Transformers
The EfficientViT model goals to enhance the efficiency of the prevailing vision transformer models using three perspectives,
- Computational Redundancy.
- Memory Access.
- Parameter Usage.
The model goals to learn the way the above parameters affect the efficiency of vision transformer models, and the way to solve them to attain higher results with higher efficiency. Let’s discuss them in a bit more depth.
Memory Access and Efficiency
Considered one of the essential aspects affecting the speed of a model is the memory access overhead or MAO. As it will probably be seen within the image below, several operators in transformer including element-wise addition, normalization, and frequent reshaping are memory-inefficient operations, because they require access to different memory units which is a time consuming process.
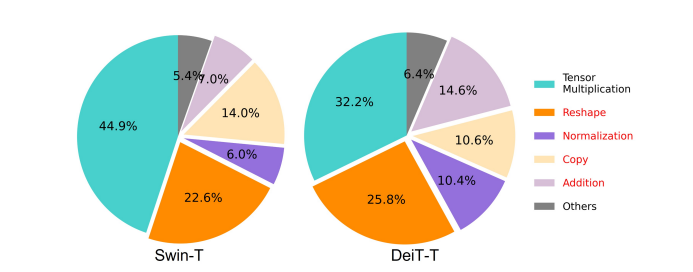
Although there are some existing methods that may simplify the usual softmax self attention computations like low-rank approximation, and sparse attention, they often offer limited acceleration, and degrade the accuracy.
Alternatively, the EfficientViT framework goals to chop down the memory access cost by reducing the quantity of memory-inefficient layers within the framework. The model scales down the DeiT-T and Swin-T to small subnetworks with a better interference throughput of 1.25X and 1.5X, and compares the performance of those subnetworks with proportions of the MHSA layers. As it will probably be seen within the image below, when implemented, the approach boosts the accuracy of MHSA layers by about 20 to 40%.

Computation Efficiency
MHSA layers are likely to embed the input sequence into multiple subspaces or heads, and computes the eye maps individually, an approach that is understood to spice up performance. Nevertheless, attention maps will not be computationally low-cost, and to explore the computational costs, the EfficientViT model explores the way to reduce redundant attention in smaller ViT models. The model measures the utmost cosine similarity of every head & the remaining heads inside every block by training the width downscaled DeiT-T and Swim-T models with 1.25× inference speed-up. As it will probably be observed within the image below, there may be a high variety of similarity between attention heads which suggests that model incurs computation redundancy because quite a few heads are likely to learn similar projections of the precise full feature.

To encourage the heads to learn different patterns, the model explicitly applies an intuitive solution during which each head is fed only a portion of the total feature, a method that resembles the concept of group convolution. The model trains different features of the downscaled models that feature modified MHSA layers.
Parameter Efficiency
Average ViT models inherit their design strategies like using an equivalent width for projections, setting expansion ratio to 4 in FFN, and increasing heads over stages from NLP transformers. The configurations of those components have to be re-designed fastidiously for lightweight modules. The EfficientViT model deploys Taylor structured pruning to seek out the essential components within the Swim-T, and DeiT-T layers routinely, and further explores the underlying parameter allocation principles. Under certain resource constraints, the pruning methods remove unimportant channels, and keep the critical ones to make sure highest possible accuracy. The figure below compares the ratio of channels to the input embeddings before and after pruning on the Swin-T framework. It was observed that: Baseline accuracy: 79.1%; pruned accuracy: 76.5%.

The above image indicates that the primary two stages of the framework preserve more dimensions, while the last two stages preserve much less dimensions. It’d mean that a typical channel configuration that doubles the channel after every stage or uses equivalent channels for all blocks, may lead to substantial redundancy in the ultimate few blocks.
Efficient Vision Transformer : Architecture
On the idea of the learnings obtained through the above evaluation, developers worked on making a recent hierarchical model that gives fast interference speeds, the EfficientViT model. Let’s have an in depth have a look at the structure of the EfficientViT framework. The figure below gives you a generic idea of the EfficientViT framework.
Constructing Blocks of the EfficientViT Framework
The constructing block for the more efficient vision transformer network is illustrated within the figure below.

The framework consists of a cascaded group attention module, memory-efficient sandwich layout, and a parameter reallocation strategy that deal with improving the efficiency of the model by way of computation, memory, and parameter, respectively. Let’s discuss them in greater detail.
Sandwich Layout
The model uses a brand new sandwich layout to construct a simpler & efficient memory block for the framework. The sandwich layout uses less memory-bound self-attention layers, and makes use of more memory-efficient feed forward networks for channel communication. To be more specific, the model applies a single self-attention layer for spatial mixing that’s sandwiched between the FFN layers. The design not only helps in reducing the memory time consumption due to self-attention layers, but in addition allows effective communication between different channels throughout the network because of using FFN layers. The model also applies an additional interaction token layer before each feed forward network layer using a DWConv or Deceptive Convolution, and enhances model capability by introducing inductive bias of the local structural information.
Cascaded Group Attention
Considered one of the main issues with MHSA layers is the redundancy in attention heads which makes computations more inefficient. To resolve the difficulty, the model proposes CGA or Cascaded Group Attention for vision transformers, a brand new attention module that takes inspiration from group convolutions in efficient CNNs. On this approach, the model feeds individual heads with splits of the total features, and due to this fact decomposes the eye computation explicitly across heads. Splitting the features as an alternative of feeding full features to every head saves computation, and makes the method more efficient, and the model continues to work on improving the accuracy & its capability even further by encouraging the layers to learn projections on features which have richer information.

Parameter Reallocation
To enhance the efficiency of parameters, the model reallocates the parameters within the network by expanding the width of the channel of critical modules while shrinking the channel width of not so essential modules. Based on the Taylor evaluation, the model either sets small channel dimensions for projections in each head during every stage or the model allows the projections to have the identical dimension because the input. The expansion ratio of the feed forward network can be brought all the way down to 2 from 4 to assist with its parameter redundancy. The proposed reallocation strategy that the EfficientViT framework implements, allots more channels to essential modules to permit them to learn representations in a high dimensional space higher that minimizes the lack of feature information. Moreover, to hurry up the interference process & enhance the efficiency of the model even further, the model routinely removes the redundant parameters in unimportant modules.

The overview of the EfficientViT framework might be explained within the above image where the parts,
- Architecture of EfficientViT,
- Sandwich Layout block,
- Cascaded Group Attention.
EfficientViT : Network Architectures

The above image summarizes the network architecture of the EfficientViT framework. The model introduces an overlapping patch embedding [20,80] that embeds 16×16 patches into C1 dimension tokens that enhances the model’s capability to perform higher in low-level visual representation learning. The architecture of the model comprises three stages where each stage stacks the proposed constructing blocks of the EfficientViT framework, and the variety of tokens at each subsampling layer (2× subsampling of the resolution) is reduced by 4X. To make subsampling more efficient, the model proposes a subsample block that also has the proposed sandwich layout with the exception that an inverted residual block replaces the eye layer to scale back the loss of knowledge during sampling. Moreover, as an alternative of conventional LayerNorm(LN), the model makes use of BatchNorm(BN) because BN might be folded into the preceding linear or convolutional layers that offers it a runtime advantage over the LN.
EfficientViT Model Family
The EfficientViT model family consists of 6 models with different depth & width scales, and a set variety of heads is allotted for every stage. The models use fewer blocks within the initial stages compared to the ultimate stages, a process just like the one followed by MobileNetV3 framework since the strategy of early stage processing with larger resolutions is time consuming. The width is increased over stages with a small factor to scale back redundancy within the later stages. The table attached below provides the architectural details of the EfficientViT model family where C, L, and H seek advice from width, depth, and variety of heads in the actual stage.

EfficientViT: Model Implementation and Results
The EfficientViT model has a complete batch size of two,048, is built with Timm & PyTorch, is trained from scratch for 300 epochs using 8 Nvidia V100 GPUs, uses a cosine learning rate scheduler, an AdamW optimizer, and conducts its image classification experiment on ImageNet-1K. The input images are randomly cropped & resized into resolution of 224×224. For the experiments that involve downstream image classification, the EfficientViT framework finetunes the model for 300 epochs, and uses AdamW optimizer with a batch size of 256. The model uses RetineNet for object detection on COCO, and proceeds to coach the models for an additional 12 epochs with the similar settings.
Results on ImageNet
To research the performance of EfficientViT, it’s compared against current ViT & CNN models on the ImageNet dataset. The outcomes from the comparison are reported in the next figure. As it will probably be seen that the EfficientViT model family outperforms the present frameworks normally, and manages to attain a really perfect trade-off between speed & accuracy.

Comparison with Efficient CNNs, and Efficient ViTs
The model first compares its performance against Efficient CNNs like EfficientNet and vanilla CNN frameworks like MobileNets. As it will probably be seen that compared to MobileNet frameworks, the EfficientViT models obtain a greater top-1 accuracy rating, while running 3.0X and a couple of.5X faster on Intel CPU and V100 GPU respectively.
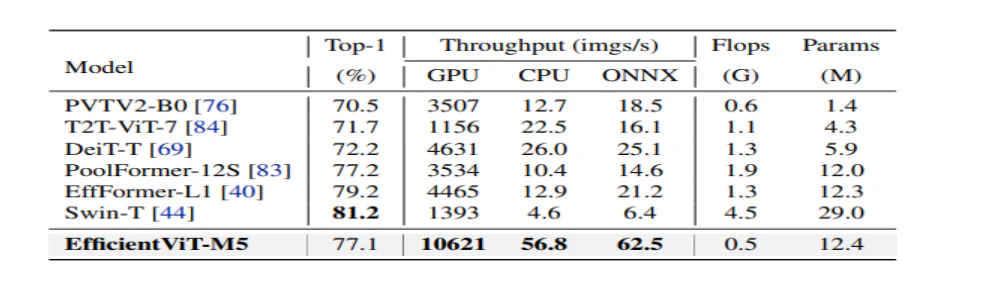
The above figure compares the EfficientViT model performance with state-of-the-art large-scale ViT models running on the ImageNet-1K dataset.
Downstream Image Classification
The EfficientViT model is applied on various downstream tasks to check the model’s transfer learning abilities, and the below image summarizes the outcomes of the experiment. As it will probably be observed, the EfficientViT-M5 model manages to attain higher or similar results across all datasets while maintaining a much higher throughput. The one exception is the Cars dataset, where the EfficientViT model fails to deliver in accuracy.

Object Detection
To research EfficientViT’s ability to detect objects, it’s compared against efficient models on the COCO object detection task, and the below image summarizes the outcomes of the comparison.

Final Thoughts
In this text, we now have talked about EfficientViT, a family of fast vision transformer models that use cascaded group attention, and supply memory-efficient operations. Extensive experiments conducted to investigate the performance of the EfficientViT have shown promising results because the EfficientViT model outperforms current CNN and vision transformer models normally. We’ve got also tried to supply an evaluation on the aspects that play a task in affecting the interference speed of vision transformers.