
Owing to a rise in natural and artificial speech synthesis approaches, one in all the foremost achievements the AI industry has achieved prior to now few years is to effectively synthesize text-to-speech frameworks with potential applications across different industries including audiobooks, virtual assistants, voice-over narrations and more, with some state-of-the-art modes delivering human-level performance and efficiency across a big selection of speech-related tasks. Nonetheless, despite their strong performance, there remains to be room for improvement for tasks because of expressive & diverse speech, requirement for a considerable amount of training data for optimizing zero-shot text to speech frameworks, and robustness for OOD or Out of Distribution texts leading developers to work on a more robust and accessible text to speech framework.
In this text, we might be talking about StyleTTS-2, a sturdy and modern text to speech framework that’s built on the foundations of the StyleTTS framework, and goals to present the following step towards state-of-the-art text to speech systems. The StyleTTS2 framework models speech styles as latent random variables, and uses a probabilistic diffusion model to sample these speech styles or random variables thus allowing the StyleTTS2 framework to synthesize realistic speech effectively without using reference audio inputs. Owing to the approach, the StyleTTS2 framework is capable of deliver higher results & shows high efficiency when put next to current state-of-the-art text to speech frameworks, but can also be capable of reap the benefits of the varied speech synthesis offered by diffusion model frameworks. We might be discussing the StyleTTS2 framework in greater detail, and discuss its architecture and methodology while also having a have a look at the outcomes achieved by the framework. So let’s start.
StyleTTS2 is an modern Text to Speech synthesis model that takes the following step towards constructing human-level TTS frameworks, and it’s built upon StyleTTS, a style-based text to speech generative model. The StyleTTS2 framework models speech styles as latent random variables, and uses a probabilistic diffusion model to sample these speech styles or random variables thus allowing the StyleTTS2 framework to synthesize realistic speech effectively without using reference audio inputs. Modeling styles as latent random variables is what separates the StyleTTS2 framework from its predecessor, the StyleTTS framework, and goals to generate probably the most suitable speech style for the input text without having a reference audio input, and is capable of achieve effective latent diffusions while profiting from the varied speech synthesis capabilities offered by diffusion models. Moreover, the StyleTTS2 framework also employs pre-trained large SLM or Speech Language Model as discriminators just like the WavLM framework, and couples it with its own novel differential duration modeling approach to coach the framework end to finish, and ultimately generating speech with enhanced naturalness. Because of the approach it follows, the StyleTTS2 framework outperforms current state-of-the-art frameworks for speech generation tasks, and is one of the crucial efficient frameworks for pre-training large-scale speech models in zero-shot setting for speaker adaptation tasks.
Moving along, to deliver human-level text to speech synthesis, the StyleTTs2 framework incorporates the learnings from existing works including diffusion models for speech synthesis, and huge speech language models. Diffusion models are frequently used for speech synthesis tasks because of their abilities to fine-grain speech control, and diverse speech sampling capabilities. Nonetheless, diffusion models should not as efficient as GAN-based non-iterative frameworks and a significant reason for that is the requirement to sample latent representations, waveforms, and mel-spectrograms iteratively to the goal duration of the speech.
Then again, recent works around Large Speech Language Models have indicated their ability to reinforce the standard of text to speech generation tasks, and adapt well to the speaker. Large Speech Language Models typically convert text input either into quantized or continuous representations derived from pre-trained speech language frameworks for speech reconstructing tasks. Nonetheless, the features of those Speech Language Models should not optimized for speech synthesis directly. In contrast, the StyleTTS2 framework takes advantage of the knowledge gained by large SLM frameworks using adversarial training to synthesize speech language models’ features without using latent space maps, and due to this fact, learning a speech synthesis optimized latent space directly.
StyleTTS2: Architecture and Methodology
At its core, the StyleTTS2 is built on its predecessor, the StyleTTS framework which is a non-autoregressive text to speech framework that makes use of a method encoder to derive a method vector from the reference audio, thus allowing expressive and natural speech generation. The style vector utilized in the StyleTTS framework is incorporated directly into the encoder, duration, and predictors by making use of AdaIN or Adaptive Instance Normalization, thus allowing the StyleTTS model to generate speech outputs with various prosody, duration, and even emotions. The StyleTTS framework consists of 8 models in total which can be divided into three categories
- Acoustic Models or Speech Generation System with a method encoder, a text encoder, and a speech decoder.
- A Text to Speech Prediction System making use of prosody and duration predictors.
- A Utility System including a text aligner, a pitch extractor, and a discriminator for training purposes.
Because of its approach, the StyleTTS framework delivers state-of-the-art performance related to controllable and diverse speech synthesis. Nonetheless, this performance has its drawbacks like degradation of sample quality, expressive limitations, and reliance on speech-hindering applications in real-time.
Improving upon the StyleTTS framework, the StyleTTS2 model leads to enhanced expressive text to speech tasks with an improved out of distribution performance, and a high human-level quality. The StyleTTS2 framework makes use of an end to finish training process that optimizes the various components with adversarial training, and direct waveform synthesis jointly. Unlike the StyleTTS framework, the StyleTTS2 framework models the speech style as a latent variable, and samples it via diffusion models thus generating diverse speech samples without using a reference audio. Let’s have an in depth look into these components.
End to End Training for Interference
Within the StyleTTS2 framework, an end to finish training approach is utilized to optimize various text to speech components for interference without having to depend on fixed components. The StyleTTS2 framework achieves this by modifying the decoder to generate the waveform directly from the style vector, pitch & energy curves, and aligned representations. The framework then removes the last projection layer of the decoder, and replaces it with a waveform decoder. The StyleTTS2 framework makes use of two encoders: HifiGAN-based decoder to generate the waveform directly, and an iSTFT-based decoder to supply phase & magnitude which can be converted into waveforms for faster interference & training.
The above figure represents the acoustic models used for pre-training and joint training. To cut back the training time, the modules are first optimized within the pre-training phase followed by the optimization of all of the components minus the pitch extractor during joint training. The explanation why joint training doesn’t optimize the pitch extractor is since it is used to offer the bottom truth for pitch curves.

The above figure represents the Speech Language Model adversarial training and interference with the WavLM framework pre-trained but not pre-tuned. The method differs from the one mentioned above as it may possibly take various input texts but accumulates the gradients to update the parameters in each batch.
Style Diffusion
The StyleTTS2 framework goals to model speech as a conditional distribution through a latent variable that follows the conditional distribution, and this variable is known as the generalized speech style, and represents any characteristic within the speech sample beyond the scope of any phonetic content including lexical stress, prosody, speaking rate, and even formant transitions.
Speech Language Model Discriminators
Speech Language Models are renowned for his or her general abilities to encode beneficial information on a big selection of semantics and acoustic points, and SLM representations have traditionally been capable of mimic human perceptions to guage the standard of the generated synthesized speech. The StyleTTS2 framework uses an adversarial training approach to utilize the power of SLM encoders to perform generative tasks, and employs a 12-layer WavLM framework because the discriminator. This approach allows the framework to enable training on OOD or Out Of Distribution texts that might help improve performance. Moreover, to forestall overfitting issues, the framework samples OOD texts and in-distribution with equal probability.
Differentiable Duration Modeling
Traditionally, a duration predictor is utilized in text to speech frameworks that produces phoneme durations, however the upsampling methods these duration predictors use often block the gradient flow in the course of the E2E training process, and the NaturalSpeech framework employs an attention-based upsampler for human-level text to speech conversion. Nonetheless, the StyleTTS2 framework finds this approach to be unstable during adversarial training since the StyleTTS2 trains using differentiable upsampling with different adversarial training without the loss of additional terms attributable to mismatch within the length attributable to deviations. Although using a soft dynamic time warping approach might help in mitigating this mismatch, using it isn’t only computationally expensive, but its stability can also be a priority when working with adversarial objectives or mel-reconstruction tasks. Subsequently, to attain human-level performance with adversarial training and stabilize the training process, the StyleTTC2 framework uses a non-parametric upsampling approach. Gaussian upsampling is a preferred nonparametric upsampling approach for converting the anticipated durations even though it has its limitations because of the fixed length of the Gaussian kernels predetermined. This restriction for Gaussian upsampling limits its ability to accurately model alignments with different lengths.
To come across this limitation, the StyleTTC2 framework proposes to make use of a brand new nonparametric upsampling approach with none additional training, and able to accounting various lengths of the alignments. For every phoneme, the StyleTTC2 framework models the alignment as a random variable, and indicates the index of the speech frame with which the phoneme aligns with.
Model Training and Evaluation
The StyleTTC2 framework is trained and experimented on three datasets: VCTK, LibriTTS, and LJSpeech. The one-speaker component of the StyleTTS2 framework is trained using the LJSpeech dataset that comprises roughly 13,000+ audio samples split into 12,500 training samples, 100 validation samples, and nearly 500 testing samples, with their combined run time totalling to just about 24 hours. The multi speaker component of the framework is trained on the VCTK dataset consisting of over 44,000 audio clips with over 100 individual native speakers with various accents, and is split into 43,500 training samples, 100 validation samples, and nearly 500 testing samples. Finally, to equip the framework with zero-shot adaptation capabilities, the framework is trained on the combined LibriTTS dataset that consists of audio clips totaling to about 250 hours of audio with over 1,150 individual speakers. To guage its performance, the model employs two metrics: MOS-N or Mean Opinion Rating of Naturalness, and MOS-S or Mean Opinion Rating of Similarity.

Results
The approach and methodology utilized in the StyleTTS2 framework is showcased in its performance because the model outperforms several state-of-the-art TTS frameworks especially on the NaturalSpeech dataset, and enroute, setting a brand new standard for the dataset. Moreover, the StyleTTS2 framework outperforms the state-of-the-art VITS framework on the VCTK dataset, and the outcomes are demonstrated in the next figure.

The StyleTTS2 model also outperforms previous models on the LJSpeech dataset, and it doesn’t display any degree of quality degradation on OOD or Out of Distribution texts as displayed by prior frameworks on the identical metrics. Moreover, in zero-shot setting, the StyleTTC2 model outperforms the present Vall-E framework in naturalness even though it falls behind when it comes to similarity. Nonetheless, it’s price noting that the StyleTTS2 framework is capable of achieve competitive performance despite training only on 245 hours of audio samples when put next to over 60k hours of coaching for the Vall-E framework, thus proving StyleTTC2 to be a data-efficient alternative to existing large pre-training methods as utilized in the Vall-E.

Moving along, owing to the shortage of emotion labeled audio text data, the StyleTTC2 framework uses the GPT-4 model to generate over 500 instances across different emotions for the visualization of favor vectors the framework creates using its diffusion process.

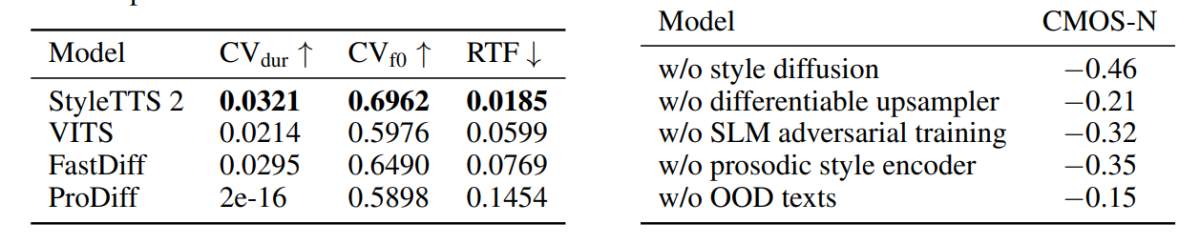
In the primary figure, emotional styles in response to input text sentiments are illustrated by the style vectors from the LJSpeech model, and it demonstrates the power of the StyleTTC2 framework to synthesize expressive speech with varied emotions. The second figure depicts distinct clusters form for every of the five individual speakers thus depicting a big selection of diversity sourced from a single audio file. The ultimate figure demonstrates the loose cluster of emotions from speaker 1, and divulges that, despite some overlaps, emotion-based clusters are distinguished, thus indicating the potential of manipulating the emotional tune of a speaker whatever the reference audio sample and its input tone. Despite using a diffusion based approach, the StyleTTS2 framework manages to outperform existing state-of-the-art frameworks including VITS, ProDiff, and FastDiff.
Final Thoughts
In this text, we have now talked about StyleTTS2, a novel, robust and modern text to speech framework that’s built on the foundations of the StyleTTS framework, and goals to present the following step towards state-of-the-art text to speech systems. The StyleTTS2 framework models speech styles as latent random variables, and uses a probabilistic diffusion model to sample these speech styles or random variables thus allowing the StyleTTS2 framework to synthesize realistic speech effectively without using reference audio inputs.The StyleTTS2 framework uses style diffusion and SLM discriminators to attain human-level performance on text to speech tasks, and manages to outperform existing state-of-the-art frameworks on a big selection of speech tasks.